
Note: If you haven’t seen Part 2-2, you can read it here.
Welcome to the third and penultimate part of my series on AGI, “Scale is All You Need?” After we approached a definition of AGI in the first part and developed a proposal to clarify the different views, the second part was about highlighting the current state of development. Where are we on the scale to AGI? What has already been achieved and what is still missing?
It turns out that many of the challenges on the way to AGI have been overcome by advances in scaling. OpenAI has demonstrated with its latest model, o1, that transformer architectures can develop excellent reasoning skills. It became clear that more test-time compute leads to better results, and the quality of the training data plays a crucial role in success. The higher the quality of the data, the more powerful the model.
However, a significant bottleneck has already been identified: the lack of agentic training data. Alexandr Wang, CEO of ScaleAI, has pointed out that the training of autonomous, agentic models is currently hampered by the limited availability of such data. ScaleAI is therefore working on transforming unstructured data into high-quality data sets to better train AI models.
“Wang emphasizes that the main problem at the moment is the lack of high-quality data. His company, ScaleAI, has therefore specialized in converting unstructured data into high-quality data sets that can be used to train AI models, including through fine-tuning, reinforcement learning from human feedback (RLHF), data labeling and curation” (“Scale is all you need?” Part 2)
However, even when sufficient training data is available, the power requirements for these models grow exponentially. Although GPUs are becoming more efficient, energy consumption continues to increase due to the increasing complexity of the models. Each new generation of AI models requires more power to support billion-parameter models, which massively increases energy requirements.
“It’s important to note that each subsequent generation is likely to be more power-efficient than the last generation, such as the H100 reportedly boasting 3x better performance-per-watt than the A100, meaning it can deliver more TFLOPS per watt and complete more work for the same power consumption. However, GPUs are becoming more powerful in order to support trillion-plus large language models. The result is that AI requires more power consumption with each future generation of AI acceleration.”
It is becoming apparent that OpenAI and Sam Altman may be right when they say that further scaling is the key to achieving AGI. However, this path presents significant challenges. The demand for compute and power is growing rapidly, and these resources are limited. Compute is essential to develop and run more complex and powerful models – for both training and inference. In the future, the demand for cloud-based AI services could skyrocket as agent swarms permeate the internet and each user potentially allows ten or more agents to work simultaneously.
However, the increasing demand for computing power also means a significant increase in power consumption. Companies like Microsoft have already secured access to enormous amounts of electricity – for example, Microsoft recently purchased 5 GW of power from the Three Mile Island nuclear power plant. Similarly, Sam Altman has made arrangements to provide 5 GW of electricity for future developments. By way of comparison, this amount of energy is enough to meet the annual needs of around three million people.
In addition to the challenges posed by compute and energy, there is also the question of social inequality: Who will have access to AGI in the future? Which nations can afford the necessary data centers, and which will become dependent? The costs and access to AGI could become the new global dividing line, between those who control this technology and those who
In this third part of the series, I will take a closer look at these bottlenecks: How much compute will we need in the future, and how realistic is it to meet this demand? What electricity demand can we deduce, and will nuclear power plants and renewable energies be sufficient to meet this demand?
In the fourth and final part, we will then look at the post-AGI society and venture a prediction of how AGI could fundamentally change our lives.
Compute
In the first section, I turn to the question and need of Compute. Recall that the term “Compute” describes the processing power necessary to execute complex calculations and algorithms. In the world of artificial intelligence, Compute is the central factor that determines how quickly and effectively systems can be trained and deployed. The more processing power available, the faster and more accurate these processes can be.
At its core, compute consists of the ability to perform mathematical operations. Computer processors, particularly chips such as GPUs and TPUs, are the fundamental building blocks that enable compute. GPUs and TPUs are specialized to process the huge matrices and vectors that feature in modern AI algorithms.
For the advancement of AI, especially in areas such as deep learning, compute power has taken on a particular significance. Deep learning is a technique based on neural networks, and these networks require immense amounts of compute power to be meaningfully trained. Each individual neuron in a neural network performs many simple operations, but when you consider that advanced networks have millions of neurons, it quickly becomes clear that the demand for computing power increases exponentially. Without sufficient compute resources, modern AI models simply could not exist, as they rely on the ability to process huge amounts of data in parallel.
Compute is essential in all areas of artificial intelligence. For training and especially for the inference of language models, or in image processing, to the extent that compute is used for the processing and interpretation of visual data. But compute is also used in robotics for control and decision-making if the robots are to act autonomously.
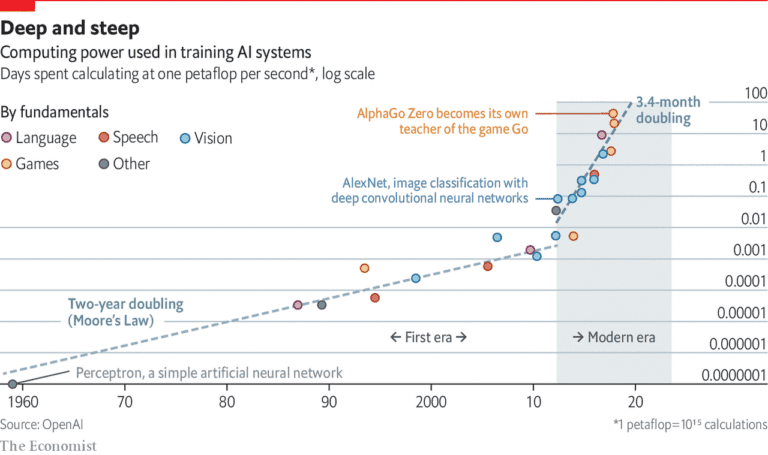
It is therefore hardly surprising that the demand for computing power has not only increased since then, but has literally exploded.
Computer power used in training AI systems has exponentially increased in the era of deep learning. (...) Since 2012, the computational resources needed to train these AI systems have been doubling every 3.4 months.

The demand for compute for new models has increased dramatically because modern AI models are becoming more and more complex and extensive. Model size has increased exponentially in recent years. This means that they contain more and more parameters. More parameters, in turn, mean more compute during both training and inference.
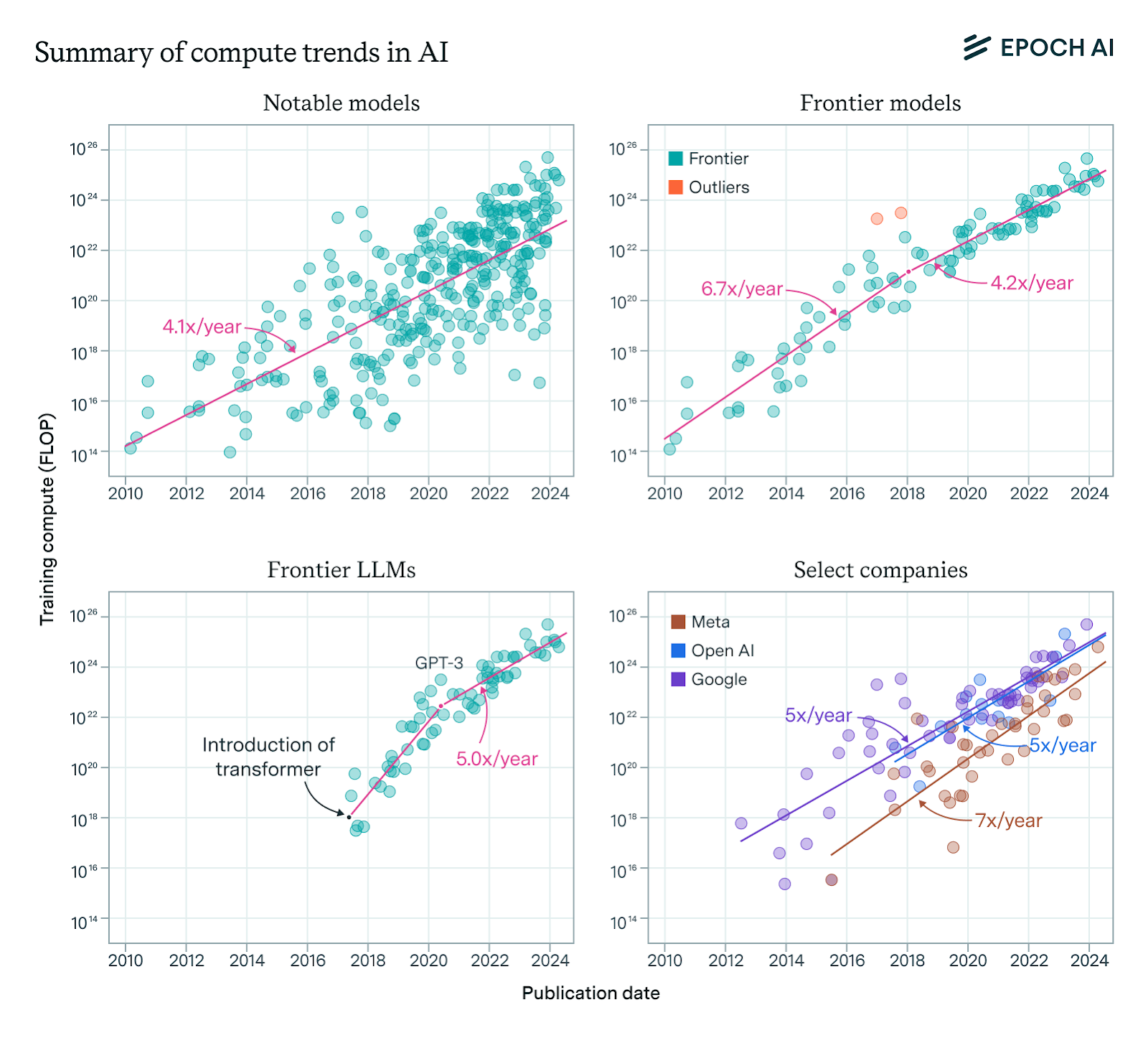
“Our expanded AI model database shows that the compute used to train recent models grew 4-5x yearly from 2010 to May 2024. We find similar growth in frontier models, recent large language models, and models from leading companies.”
However, the consequence of more compute is not only higher power consumption (which I will discuss in the following chapter), but also simply higher costs. Training your own models is a very expensive undertaking and not many tech companies can afford to play in the AI league. In order to refinance itself, OpenAI has therefore recently raised the possibility of primarily converting its legal form into a for-profit organization.
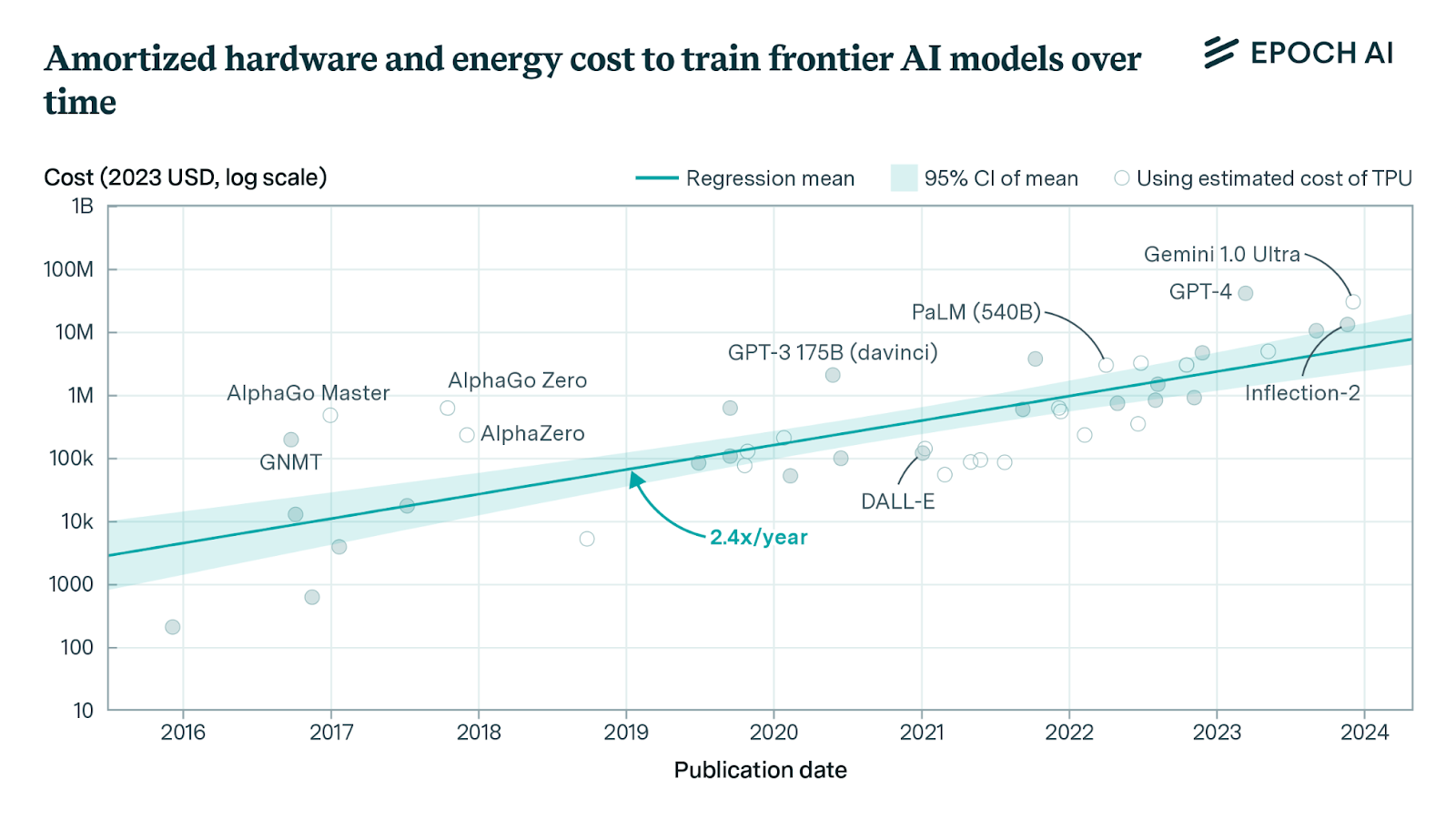
The cost of training frontier AI models has grown by a factor of 2 to 3x per year for the past eight years, suggesting that the largest models will cost over a billion dollars by 2027.
The costs of new models increase exponentially when the models grow by an OOM (Order of magnitude). This was also recently confirmed by OpenAI's CFO Sarah Friar in an interview with CNBC.
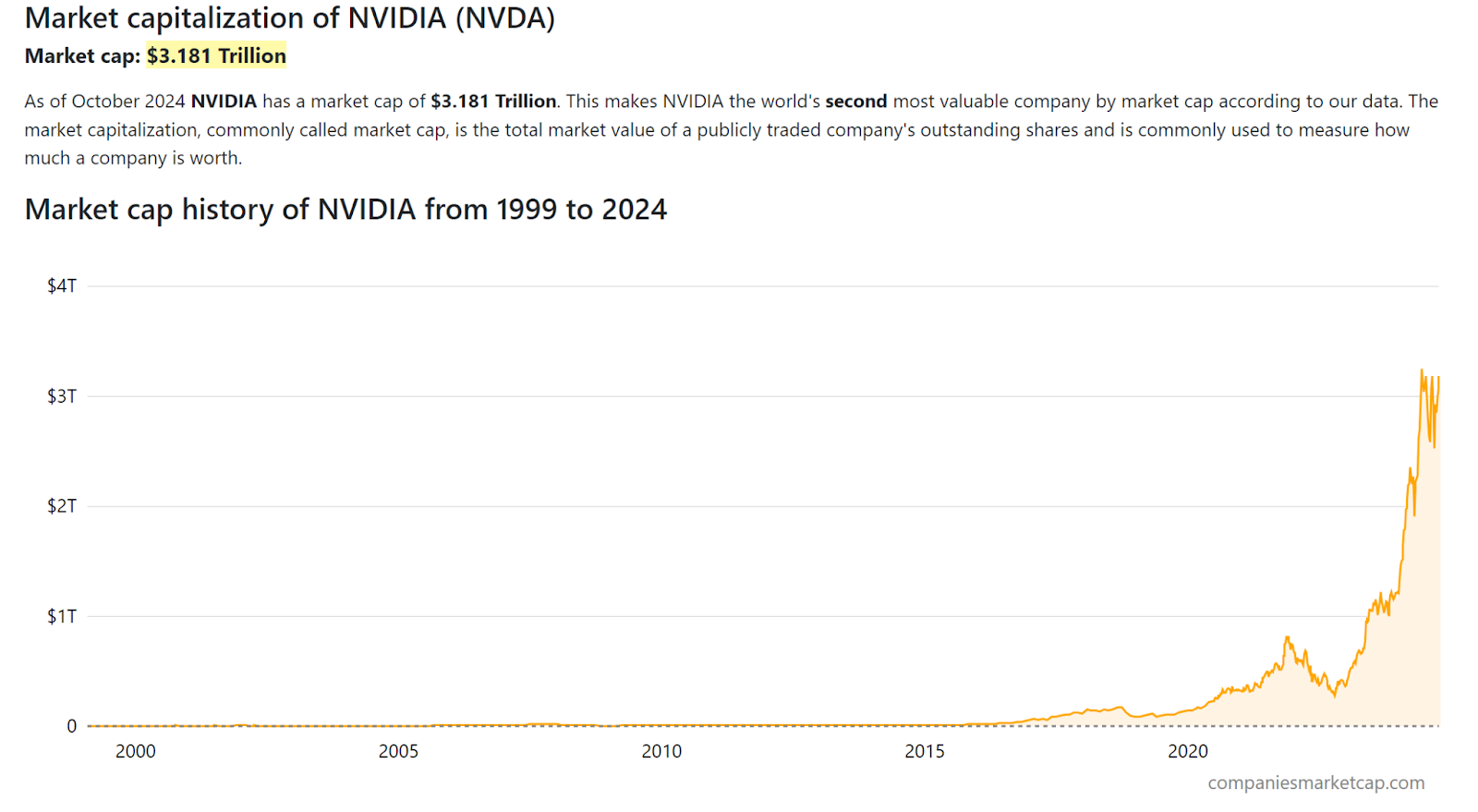
Since larger models continue to achieve better results, all large tech companies continue to rely on larger models. So far, the biggest beneficiary of this is NVIDIA. There is a little anecdote in the financial industry that says that the biggest profiteers during the gold rush in the 1860s in the US were not the gold prospectors themselves, but the shovel manufacturers, because not everyone found gold, but everyone needed a shovel to search. To remain in this anecdote metaphorically, one can say that today the biggest profiteer of artificial intelligence is NVIDIA, because today's shovels are clearly GPUs and the demand for compute will certainly not stop in the near future. In any case, the stock market, where the future is always traded, is optimistic about NVIDIA's development. Also because all the big tech companies are courting NVIDIA. (In the following chart, you can clearly see how NVIDIA's share price boomed with the advent of the transformer architecture around 2017.
Mark Zuckerberg said on Meta’s second-quarter earnings call on Tuesday that to train Llama 4, the company will need 10x more compute than what was needed to train Llama 3. But he still wants Meta to build capacity to train models rather than fall behind its competitors.
The amount of computing needed to train Llama 4 will likely be almost 10 times more than what we used to train Llama 3, and future models will continue to grow beyond that…
And scaled up to the training of Llama 4 405b, one could assume a tenfold increase in computes – provided Meta doesn't plan for a tenfold increase in training time.
“When we talk about a tenfold increase in computational requirements, it's crucial to grasp the scale of what this means. The recently released Llama 3.1 405B model, boasting 405 billion parameters, required over 16,000 H100 GPUs for training. Extrapolating from this, Llama 4 could potentially necessitate around 160,000 GPUs or equivalent computational power.”
In short, an end to the demand for computers is not in sight, and fewer and fewer tech companies can afford to be in the race for the best model. In addition to computer demand and the associated costs, electricity demand is also one of the other outstanding problem.
Part 3-2 is coming out tomorrow. Subscribe to the Forward Future Newsletter to have it delivered straight to your inbox.
About the author

Kim Isenberg
Kim studied sociology and law at a university in Germany and has been impressed by technology in general for many years. Since the breakthrough of OpenAI's ChatGPT, Kim has been trying to scientifically examine the influence of artificial intelligence on our society.
![[Sources] Part 3_ bottlenecks and AGI.pdf](https://media.beehiiv.com/cdn-cgi/image/fit=scale-down,format=auto,onerror=redirect,quality=80/static_assets/file_attachment.png)

